
Paper Statistics with TimeTracker
A few years I did a comprehensive breakdown of how much writing the various sections of the HOOT paper required. What surprised me was how many more times some sections, like the introduction, were rewritten, compared to the technical sections, which only had to be written and edited a few times. This post is a sequel: I want to look at how hard each section was to write, not how much editing it took.
Gathering the data
To answer this question, I'm going to use TimeTracker, a project Cathy and I wrote years ago and that I've been using since. TimeTracker runs in the background and records the title of the currently-active window every second. This makes for a giant dataset of what you were doing at any point in time. The project also includes a convenient GUI for looking at this data and doing searches on it.
I loaded up the data from my home and work laptops and searched both of them for Emacs: ~/cassius/papers/. This gives me every line from when I was using Emacs, with the current window pointing to a file in the paper's repository. Emacs shows this information in the window title thanks to the following code in my .emacs:1 [1 My full dotfiles are also all on GitHub.]
(setq frame-title-format '((:eval (if (buffer-file-name) (concat "Emacs: " (abbreviate-file-name (buffer-file-name))) "Emacs: %b"))))
Unfortunately, right now TimeTracker doesn't have the ability to load two different log files (one from the work and one from the home computer) and collate them, so I've done the collation manually in Google Sheets.2 [2 I've since added that feature.]
The results
In total, I spent 25 hours typing things into Emacs when writing this paper. Of course, this does not represent the total expended effort on the paper. It does not count the huge contributions of my co-authors, nor the time spent tweaking the tool, running experiments, or reading paper drafts; and it hides the time spend discussing the paper with others or planning paper sections. Still, it's useful and interesting data.
Here's the TimeTracker GUI, marking times when I was working on the paper:3 [3 This is a composite of two files, so it has some weird artifacts; please ignore them.]
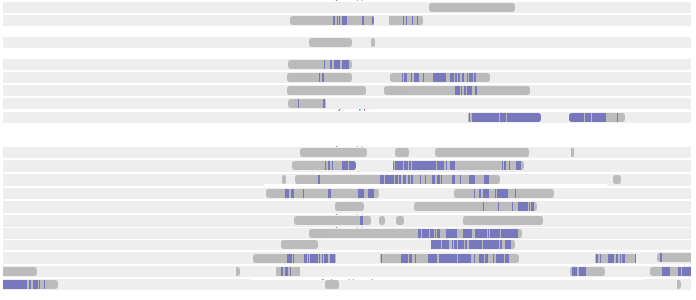
You can see that I had pretty consistent working days, running roughly 10:00 to 18:00, except for late nights and one all-nighter as the last few days of the deadline came near.
Since I'm recording file names, I can compute total time per section. The raw results:
| Section | Time | Section | Time | Section | Time |
|---|---|---|---|---|---|
| assertions.tex | 6:24 | floats.tex | 6:07 | semantics.tex | 3:04 |
| eval.tex | 1:40 | language.tex | 1:36 | intro.tex | 1:06 |
| overview.tex | 1:01 | related.tex | :59 | encoding.tex | :53 |
| im/runtime.py | :37 | references.bib | :17 | main.tex | :16 |
| background.tex | :16 | visual-testing.txt | :12 | im/floats.tex | :11 |
| abstract.tex | :11 | stats.rkt | :09 | im/insts.py | :08 |
| im/runtime.tex | :07 | macros.tex | :03 | data/all.log | :02 |
| Makefile | :02 | appendix.tex | :02 | im/insts.tex | :01 |
Interesting trends
In this paper, the technical sections were assertions, floats, and semantics, and encoding, while the non-technical sections were intro, overview, eval, related, and background, plus the various figures and so on. So you can see that, though this paper like the HOOT paper doubtless had many rewrites of the non-technical sections, that wasn't where I spent the majority of my time. That must be because of my wonderful coauthors,4 [4 Adam Timothy Geller, Shoaib Kamil, Zachary Tatlock, and Michael Ernst] who allowed me to focus my time on the technical sections while they improved the writing on the non-technical sections.
It also demonstrates a key subtlety to my earlier result that the non-technical sections require the most rewriting: the technical sections may require fewer rewrites, but writing those sections is much harder, because of the more complex ground they cover. They are also more formally demanding: there is no strictly correct or incorrect introduction to a paper (which means more rounds of rewrites), but there is correct and incorrect technical meat. This observation is buoyed by the fact that he most time-consuming section in this paper was assertions, which was series of detailed technical case-studies: lots of rewriting, but also technically-demanding.
Another interesting fact I noticed was that the sections had a roughly power-law distribution of effort. When I looked into that more, I found that the n-th most time-intensive section took roughly 1/n as much work as the most time-intensive section (a Zipf distribution). Here that is in plot form, plotting how many times longer the most time-intensive section was than the n-th most time-intensive:
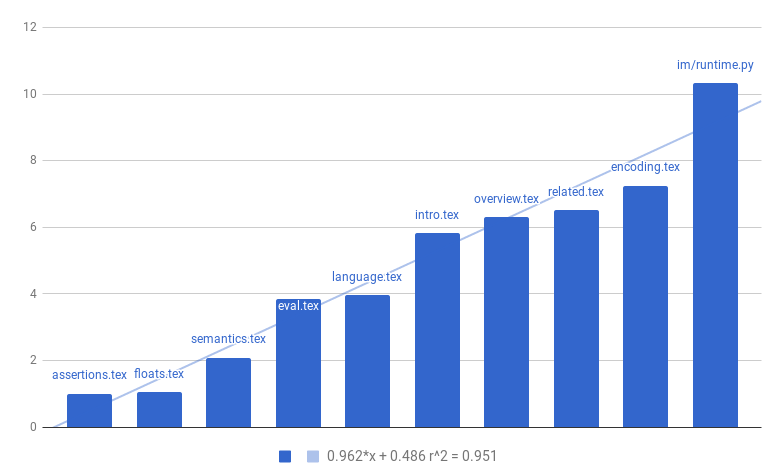
The \(r^2\) on that line is quite good, 95%, so it seems like the trend I noticed is quite accurate.
Conclusions for paper writing
The most important conclusion that comes to mind, having seen this data, is that it's much more important to guess which section will be most difficult than to guess how many sections there are. I tend to writing papers from the front to back—that is, I'll draft the sections in roughly textual order (maybe I will skip the background and related work until later) and then edit them as necessary. When I plan out this task, I tend to estimate it as a fixed number of sections, since I draft each section in one sitting. If sections take vastly-different amounts of time, it may be more important to estimate my confidence that any particular section will be the "big one".