
How Herbie Happened
Over winter break, I decided to dig into my notes and try to sketch
out the history of the Herbie project. Besides a fun exploration of
our git history, I was hoping to crystallize some of the lessons I
learned from the project. Besides being my first successful research
project in general, I think Herbie taught me a few particular lessons:
- Tackle ambitious problems
- I don't work well alone
- Good benchmarks guide research
- Generating reports from search processes is great for debugging
- You never know what will be important
- Some small things matter a lot
- Don't submit papers too early
- If you keep rewriting something, think deeper
- Make a demo
Genesis
The idea for Herbie was born in my lab's PL reading group when we read Barr, Vo, Le, and Su's Automatic Detection of Floating Point Exceptions. The paper finds inputs that cause floating point overflow and underflow. As we discussed the paper, my advisor asked why a program couldn't fix the problems after detecting them.
I'd taken a numerical analysis course in undergrad, and remembered numerical problems being extremely hard. But my advisor's infectious optimism got the better of me. As far as either of us knew, there was no work out there on automatically improving the accuracy of floating point programs. The problem seemed so important that even if our attempts accomplished little, we could likely still publish any marginal progress. So Herbie was born—with the goal of turning a quick run at a hard problem into a minor publication.
Though the exploitative approach to research problem selection doesn't sound that noble, it did bring me to work on an important and ambitious problem. And I'm still not sure that exploitation is the wrong approach. If a problem has been understudied, why not go after small gains? Herbie tackled ambitious problems. Even small steps would be success.
To improve accuracy automatically we could measure accuracy, apply some rewrite rules, and keep the results if the accuracy improved. It'd be a search process. James realized that we could measure accuracy by evaluating the same program in both single- and double-precision floating point, and wrote up a quick Haskell implementation. I abandoned the language immediately.1 [1 I'd spent two years working with Jerry Sussman at MIT, and wasn't about to give up working in a Lisp.] The next step was to build the pattern-matching search. The first pass of that used something like an A* search with exactly one rewrite rule. It could solve the one example we used as a test case, and nothing more. Of course, our initial attempt was trash. A* search isn't very good, measuring accuracy by maximum error is a very bad way to guide a search, and of course we needed lots more rewrite rules. But we were off to the races.
At this point, my advisor Zach suggested that I collect other test cases. If you've only got one test case, and your tool works on that test case, it's very difficult to make any further progress. The first benchmarks I found were from the Math.js library; Herbie eventually repaid the favor by finding and fixing several numerical accuracy bugs in it. I then added Hamming's NMSE benchmarks. This was a crucial find, because solving these benchmarks required us to invent the many techniques now found in Herbie. Benchmarks guided the whole research project. Herbie wouldn't have happened without the wonderful selection found in Hamming's book.
Finding the NMSE benchmarks was a story in and of itself. Neither Zach, James, Alex, nor I had any “real” experience with numerical analysis2 [2 Few people do these days!] and we decided it'd be best to have some background reading to get us up to speed. So we went on Amazon, searched “Numerical Analysis”, and bought the top-ranked book. This worked well! It's probably worth trying for other topics. NMSE was especially useful, because it had a chapter dedicated to the task Herbie was doing, so we could just take all of the problems and examples from that chapter. Better yet, we could use the solutions to the problems and exercises as “targets” for Herbie to aim for. (These days, Herbie surpasses several of the targets…)
The first version of the framework I wrote to run these benchmarks was awful: each benchmark was a self-contained Racket program that would import the Herbie code,3 [3 At this point, Herbie was called Casio. We changed the name to avoid trademark issues later on.] run Herbie, and compare that to a known-good output. This ugly system made the benchmarks code instead of data; this is bad for benchmarks, which should be written once and then last through many changes to the project.
Throughout these first few months, I found my work on Herbie slow, purpose-less, and demotivating. I had by this point been in Seattle for three months—I had not yet made new friends, and both my research projects (Herbie and HOOT, a failed distributed systems project) were barely moving. Both were also largely solo projects, and solo projects don't work for me.
First breakthroughs
Handling these additional benchmarks required some more rewrite rules like associativity and commutativity. Unfortunately, our search process couldn't make much headway with these rewrites—commutativity and associativity meant that every program had dozens of alternatives. Finding a sequence of rewrites longer than a single step took forever.
In mid-December, things began to turn. We made several important technical changes: we switched to evaluating accuracy with MPFR, switched from maximum to average error, and added error localization, which made the first significant advance over A* search. We also made an important social change: Alex joined the Herbie project. With two people at work, the project moved faster and was much more fun.
This phase also made an important change in helping us understand Herbie: we made every program variant produced by Herbie track the changes that had produced it. This was the foundation for the reports now produced by Herbie, and was invaluable in debugging the search process.
Reporting was crucial for helping us make progress with Herbie. Search processes can be hell to debug, because they can both route around bugs and also take the wrong path without leaving a trace as to why. By adding the change-tracking and reports infrastructure, we always had some basic insight into how Herbie worked, and that led to numerous insights into how to improve it. (I also later wrote a shell to step through the Herbie process manually. I don't think we used it much, but it would later inspire Alex's method of stepping through Herbie at a REPL, which is still part of the Herbie code.)
As I worked on code cleanup and localization, Alex worked on history simplification, an interesting feature that we eventually abandoned. The idea was that any search process, like our A* search, frequently found good changes but only after making several irrelevant changes first. To get rid of them, you have to separate the irrelevant changes from the ones necessary to support the eventual valuable change; and then somehow redo the useful changes without the useless ones. We used a variant of the operational transform to do this, inspired by my simultaneous work on HOOT. I still think history simplification was a cool idea, though it'd be hard to apply to modern Herbie. I wonder if other search algorithms do anything like it.
By now, Herbie was starting to solve benchmarks. The error localization allowed Herbie to find the right place to apply rewrite rules, which meant that if only one rule application was necessary, Herbie would find it before too long. And “zaching” helped produce weird but sometimes useful rewrites. Multiple rule applications, however, were still impossible.
Sidelining search
Herbie needed multi-step rewrites, and search algorithms weren't cutting it. We decided to side-step the issue and build an algebraic simplifier. For reasons I no longer remember, Alex took charge of that project. Alex handled it well, but I'm not sure why I entrusted such a big component to a still new and unproven undergraduate. Perhaps we all recognized Alex's skill early; or perhaps we didn't think simplification would be that important. In fact, simplification is the most important component in Herbie. You can never tell what will end up mattering. Alex quickly wrote a working simplifier, and Herbie could suddenly solve four or five of the Hamming examples to our satisfaction. However, the simplifier was buggy and would sometimes mangle programs.
The next core algorithm to fall into place was regime inference. Zach and I had discussed regime inference before, but looking more carefully at our benchmarks showed us an example where it would matter. Alex wrote the first version of regime inference; it did not use dynamic programming like it does now. Instead, it used a heuristic to find the longest mostly-uninterrupted sequences of points where one program was better than the other. If I recall correctly, the regime inference code did help for several examples, but was rickety and hard to predict.
If Alex was writing two core algorithms and working with Zach to document them,4 [4 This commit is empty because we eventually filtered the repository to remove the documentation. I assure you there once was an impressive multi-page tech report in progress here.] what was I doing during this time? If memory serves, I was reading and digesting a large body of numerical methods literature, especially the work of Prof. Kahan. This didn't immediately translate into code, but gave me good ideas further down the line.
The first idea was to use ULP, not relative error, to measure the accuracy of program variants. Though obscure and technical, this turned out to be a very important change. In some deep sense, average ULPs were the right measure of error for Herbie, while relative and absolute error were shoddy approximations to it. Before this point I remember frequently ascribing a problem to error measurement, or finding a hack to work around error measurement problems. Once ULPs were in place, those problems vanished. Some small things matter a lot, though of course you can never tell what will end up mattering.
Now that we had good error measurement and several benchmarks solved, it was starting to become important to run our benchmarks frequently and analyze the results. To help with this, Alex put together a report generator, which would run Herbie and produce a table with results. The reports infrastructure went through several rewrites, but was a major factor to the eventual success of Herbie.
The next big advance in Herbie was to generate multiple changes at a time using recursive rewriting. The idea is that in order to apply a rewrite rule to an expression, it may be necessary to rewrite the expression's children first. Implementing this idea solved several more benchmarks, and at this point we were seeing Herbie do some interesting and non-trivial things.
ASPLOS push
At this point, we mostly halted new code work to switch to writing a paper. Our goal was ASPLOS. My memory here is hazy, but at this point we improving roughly half of the Hamming benchmarks. That seemed pretty good.
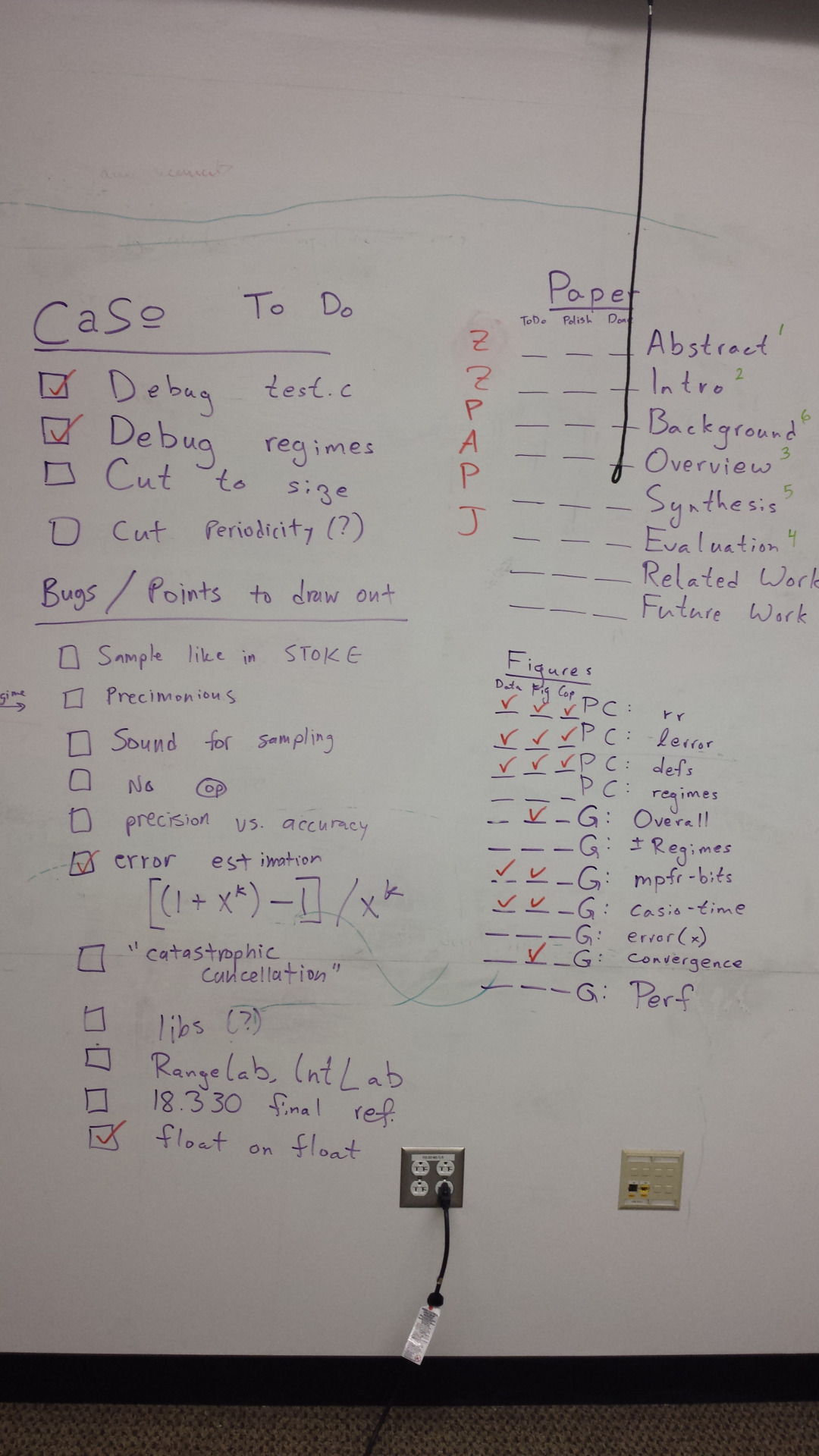
Figure 1: Our ASPLOS todo-list, close to deadline.
Herbie's recursive rewriting, localization, and simplification were yielding good results, but were also fragile and buggy. The next few months, from May through August, saw rewrites of each of these systems. Simplification was, I think, rewritten twice, though still staying a recursive, heuristic, top-down algorithm. The main loop was rewritten once or twice as well.
In a major rewrite, regime inference moved to the dynamic programming algorithm currently in use. Regime inference had been a mess of parameters to tweak and heuristics to adjust, and had been correspondingly creaky, unpredictable, and buggy. We came up with the dynamic programming algorithm by locking ourselves in a room for two hours, and emerging with the whole thing figured out.
I wrote a complex periodicity analysis to find the parts of the
program that were periodic like sin x. It turned out that we didn't
have anything useful to do with those parts once we found them,
though. We'd been hoping to create periodic regime branches, but they
turned out not to help much.
We also did quite a bit of work to speed up Herbie; the Hamming benchmarks were taking an hour to run. We fixed the exact evaluation, added a cache for localization, and killed a log that was eating several GB. Memory problems were actually a recurrent problem in Herbie—not problems with the garbage collector, just problems keeping too much stuff around.
To set ourselves up for publication, I added benchmarks by scanning random articles in Physical Review A 89. I'm not sure how I got that idea, but I found out that half of the formulas from physics papers have a numerical problem that Herbie can detect, and about half of those Herbie can improve (though it was fewer when we gathered the benchmarks).
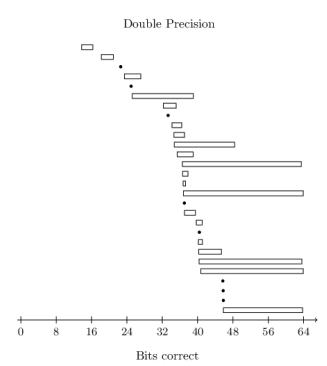
Figure 2: Our ASPLOS results. The arrow plot hadn't been invented yet.
Our paper push led to us roping James back into the project, now to gain access to his Tikz skills. James came up with the pre-cursor of the arrow graph we now use for showing error improvement, and gave lots of very useful writing feedback.
At the last minute before submitting the Herbie paper to ASPLOS, we decided to postpone the paper to PLDI. It was pretty tense: we had a paper written, good results, and were ready to submit. And as Zach is about to press the submission button, he turns to us with a mischievous grin and asks, “Guys, what if we didn't submit the paper?” I wouldn't recommend pulling this trick on your junior grad students, but in this case, it worked out. We thought Herbie could be even better, and PLDI wasn't far away.
PLDI push
We withdrew the paper and all went to grab a beer.5 [5 Even Alex, who was underage at this time. The statutes of limitations have expired.] Over beer, we discussed the next steps for Herbie, including convincing Zach that the whole thing shouldn't be rewritten in OCaml. But we also settled on big plans: equivalence graphs for simplification, automatic Taylor expansions, faster sampling, and a new search algorithm.
I still felt excited about the project, and didn't want to publish a bad paper when we could have a good one a few months later, so I managed to take our non-submission in stride. I think Alex did too. The usual academic wisdom is to publish early and often: it gets your work out to others, claims priority, and worst case you'll publish a second paper improving on the first. But in this case I think the right move was not publishing yet. The final PLDI paper we published was much stronger, and was also easier to read and understand thanks to the extra time we had to polish it.
After the disappointing ASPLOS push, we only had a few months to improve Herbie for PLDI.
My first instinct after a failed paper push was to clean up the code to set up for the next phase of Herbie. This meant cleaning up the build system (ick! But I learned a lot of Make magic), a fresh coat of paint on the reports infrastructure (like a parenthesization algorithm to print nice TeX), and an expanded logging infrastructure to help debug Herbie. This is when we added sampling distributions to Herbie.
It was also a time to undo some bad design decisions from months ago, like removing lattice-based sampling, which led to both unstable and slow sampling for programs with many variables, and implementing a main loop based on a new pruning algorithm, which would keep any program variant that was the best program yet seen on some input point. I also made an abortive attempt at yet another simplification algorithm, which was never as good as Alex's, but which is still in Herbie because series expansion uses it.
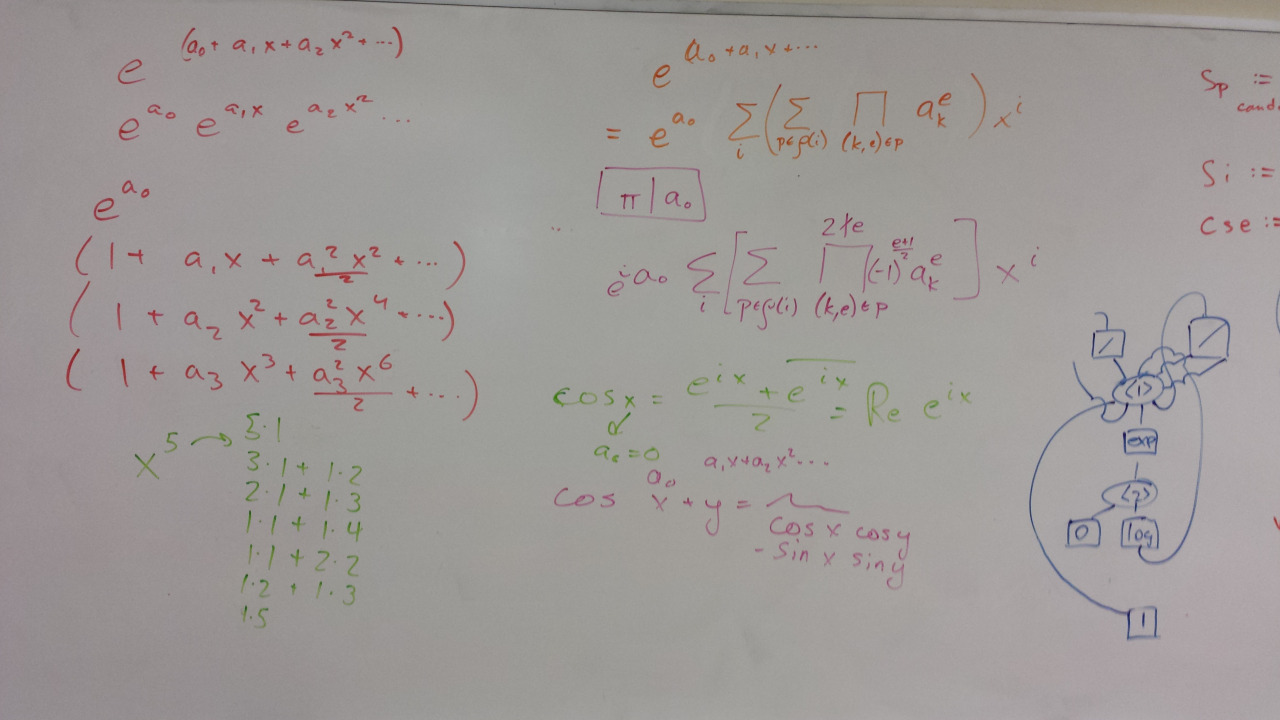
Figure 3: Series expansion and equivalence graph simplification on one whiteboard.
In the months leading up to PLDI, Alex and I worked in parallel on two big features. I worked on series expansion and invented an algorithm I've written about before. I think series expansion is the part of Herbie I am proudest of: it is both mathematically interesting and technically important.
Alex, meanwhile, worked on the egraph-based simplification algorithm, the goal of which was to end our quarterly cycle of rewriting the simplification procedure. Egraph simplification may be the most technically challenging algorithm inside Herbie; it is the part of the code base that I am most afraid of. Egraph simplification worked splendidly. Though we've had to tweak its performance quite a lot, it's never been as finicky or unpredictable as the many previous iterations of simplification had been. It was eye-opening, too, that that improvement required switch from a natural top-down simplification algorithm to a weird new thing from the compilers literature. If you keep rewriting something, think deeper. The algorithm you're using is somewhat appropriate, but not appropriate enough, and you can do better.
Egraph simplification and series expansion were committed within days of each other, and Herbie immediately shot from solving half to all but a few of the Hamming examples.6 [6 These days, we solve all but one, usually.] We turned to paper-writing again, aiming to put together the best paper we could for PLDI. Since our results were now quite good, we could focus on running additional experiments, writing a very clear paper, and trying some variations of our code to make Herbie not only work well but also be easy to explain.7 [7 This is when we took out Zaching and periodicity analysis.] Writing the paper twice made the second pass much better.
After PLDI
Two weeks’ break followed PLDI, and then a new round of project
management began. Zach put together a simple web page to collect the
reports we'd gathered, and this dashboard morphed into the project web
page when we decided to open-source our code.8 [8 Actually, I think
the plan was to open source all along, but somehow we felt unsafe
doing this before publication.] This was quite a process, because we
wanted to keep our paper drafts out of the public eye.9 [9 You never
know when you've said something impolite about someone else's work…]
Luckily, git has some tools for this, and those tools are why, looking
through our commits, you see lots of empty ones.

Figure 4: Zach, Alex, and I filming the Herbie video abstract.
When the time came to present Herbie at PLDI, we put together the online demo. The demo is the version of Herbie that's had the most impact. Make a demo for your own projects. It's a great interface for Herbie; I'm hoping to one day make it the standard way to use Herbie (but right now the code needs cleaning up).
After publication, our work on Herbie became much slower. We released a 1.0, standardized our input format, and set up regular regression testing. We also gained users, with a GHC and a Rust plugin calling out to Herbie. But it stopped being my main job, and Alex too moved on to Herbgrind.
Herbie is still seeing regular work. There's a 1.1 release coming soon, and I continue to maintain it. If you're looking for automatically improving floating point accuracy, check it out.
Footnotes:
I'd spent two years working with Jerry Sussman at MIT, and wasn't about to give up working in a Lisp.
Few people do these days!
At this point, Herbie was called Casio. We changed the name to avoid trademark issues later on.
This commit is empty because we eventually filtered the repository to remove the documentation. I assure you there once was an impressive multi-page tech report in progress here.
Even Alex, who was underage at this time. The statutes of limitations have expired.
These days, we solve all but one, usually.
This is when we took out Zaching and periodicity analysis.
Actually, I think the plan was to open source all along, but somehow we felt unsafe doing this before publication.
You never know when you've said something impolite about someone else's work…